

The Google Books project is a wonderful, vital enterprise with the potential to open up new quantitative ways to deeply explore culture, history, and language. And so it was with much anticipatory rubbing of hands together that we dove into the data set to see what we could find about the evolution of language. And then, after some standard suffering, and with much sadness, we found we had to close this New Box Full of Glorious Data and walk away, and write a paper we didn’t expect to write.
What we found, nutshellingly:
- Big problem #1: The popularity of books is not incorporated into the database, but the corpus is widely used with the presumption that it is. A Harry Potter book has the same influence as the most obscure tome.
- Big problem #2: The main database is increasingly filled with scientific literature throughout the 20th Century—the corpus reflects the growth of science during this time rather than literature and culture.
- Possible fix #1: Popularity will be the much harder issue to contend with, and will need some kind of sales or reading estimates. Until this is done well, all observations of cultural evolution should be met with a great deal of skepticism.
- Possible fix #2: To cope with the rise of science and other problems, the Google Books Project needs a lot more metadata. In principle, this seems doable based on the data Google must already have. Too many books and book-like things (journals) are being smooshed together.
Any scientific analysis of the n-gram database has to be performed very, very carefully. A great many existing studies need to be reconsidered. Some results will hold up, some results won’t.
Every book is equal—The Google Books project is a library without circulation data.
The corpus fails to represent popularity of words and phrases because it is (1) library-like, meaning it contains one of each book; and much more problematically: (2) overwhelmed with scientific and medical literature. The second Fiction corpus may be okay but all preceding work is compromised.
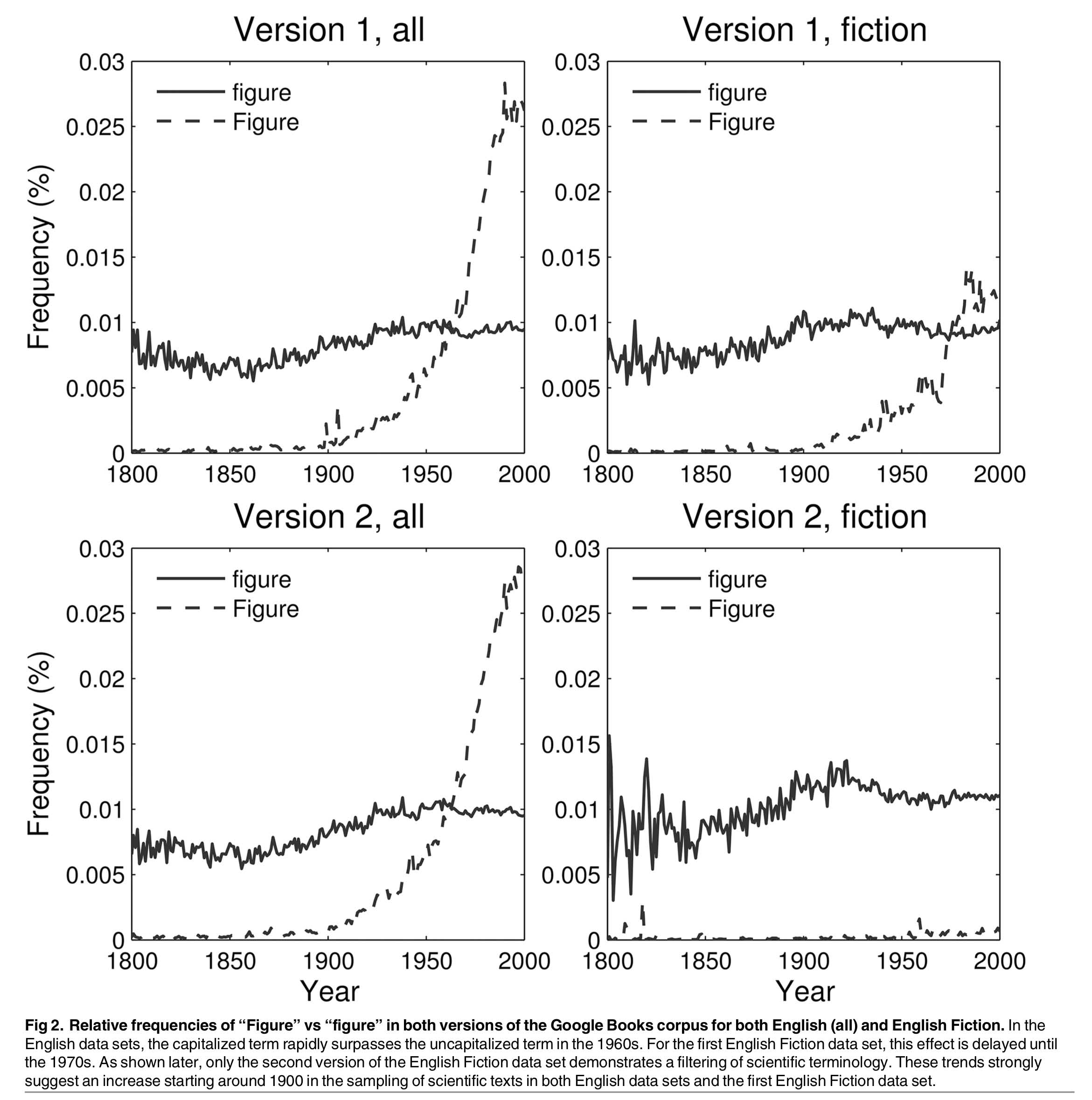
The “Figure” figure—Since parsing in the data sets is case-sensitive, we can give a suggestive illustration of the contribution of scientific literature. The picture below displays the relative (normalized) frequencies of “figure” versus “Figure” in both versions of the corpus and for both English and English Fiction. In both versions of the English data set, the capitalized version, “Figure,” surpasses its lowercase counterpart during the 1960s. Since the majority of books in the corpus originated in university libraries, a major effect of scientific texts on the dynamics of the data set is quite plausible.
“I can make graphs so it must be right. Right?”—The n-gram viewer is fun but easily produces very misleading trends. Despite our warnings, and those of many others, individuals continue to make casual claims about cultural evolution. Most recently, Jonathan Merritt published an opinion piece in the New York Times claiming that n-gram data “shows that most religious and spiritual words have been declining in the English-speaking world since the early 20th century.”
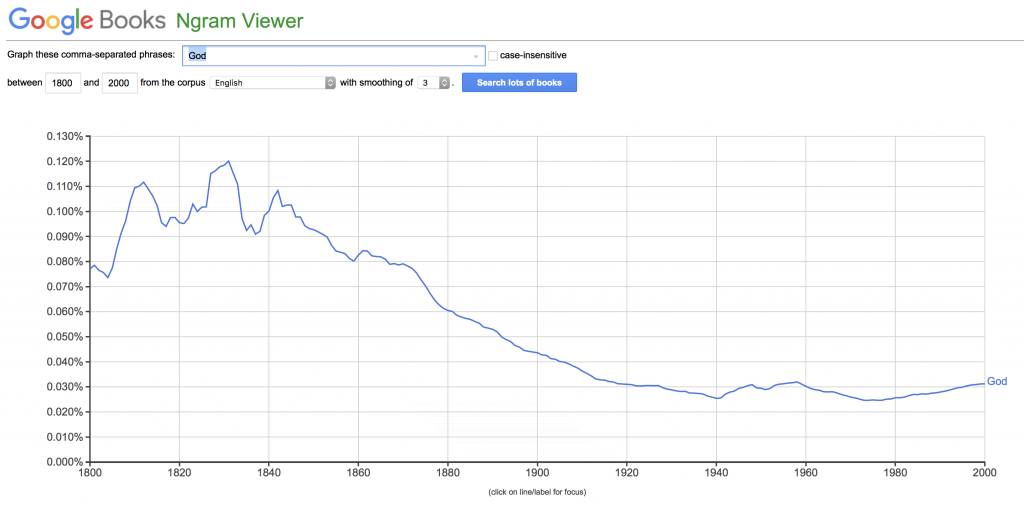
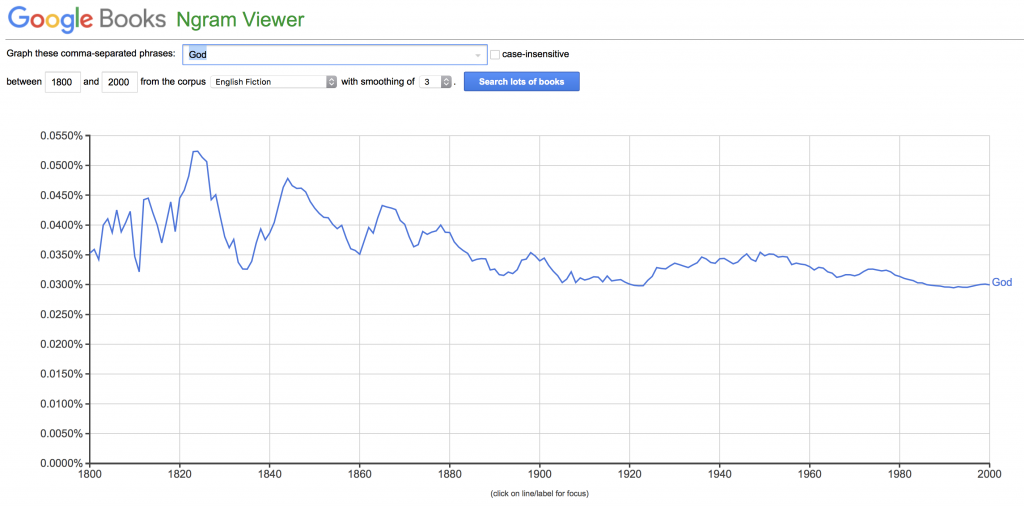
While this statement could certainly be true, the default “English” n-gram data is not able to support the claim. Merritt is likely referring to trends like figure 5h in the original Culturomics paper, which demonstrated a relative decrease in the word “God”, but the trend largely disappears when looking at English Fiction alone.
The most excellent Mark Liberman dug deeper into the purported decrease in spiritual words as well.
If Google insists on including textbooks & scientific studies, their n-gram viewer should default to display “English Fiction”, the least troublesome version, rather than “English”. Otherwise, unsuspecting cultural scholars will continue to be misled by decreasing 20th-century relative word frequencies.
Other problems—More recently, the whole thing has been thrown by a change in which books are chomped and scanned. We and many other researchers had noticed issues with peculiar trends going beyond the year 2000, and we consequently restricted our analysis to 1800 to 2000, with the thinking that we had to first sort out this reasonable looking part (oops). Trends for words and phrases are doing crazy things after the year 2000, and nothing should be inferred from this behavior, but unfortunately it’s terribly easy and tempting to do so because of the excellent n-grams interface.
What to do?—Google operationalized a solution to a critical modern math problem: organizing the Internet. Their reputation gives people the impression n-grams data is rock solid, when in fact it is very messy, and would be much more useful if curated carefully. The n-gram interface is simple, clean, and powerfully misleading. The whole project needs to be overhauled immediately.
The paper: E. Pechenick, C. M. Danforth, P. S. Dodds. 2015. PLoS ONE. Characterizing the Google Books Corpus: Strong limits to inferences of socio-cultural & linguistic evolution. Journal URL
Some press: The pitfalls of using Google Ngram to study language. Wired.
Some relevant tweets:
Never bring statistical arguments to a story fight.
— Peter Sheridan Dodds (@peterdodds) October 15, 2018
If you want to look at how something changes over time, you need to be sure the changes you see aren't artifacts of changes in your data. https://t.co/khsKi9eVPU
— Calling Bullshit (@callin_bull) October 18, 2018